- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
语音转写产品在法律行业形成深度适配的应用方案,满足专业场景需求。在庭审场景中,产品支持 “庭审专属模式”,可精细识别法官、律师、当事人等不同角色语音,自动标注发言主体,转写内容实时同步至庭审记录系统,同时支持与庭审录像联动,点击文字即可定位对应录像片段,便于后续庭审回顾与证据核对;在律师办公场景,产品内置法律专业词典,涵盖 “诉讼时效”“管辖权” 等海量法律术语,确保合同谈判、案件讨论的语音转写准确无误,转写后的文档可直接生成标准法律文书格式(如起诉状、辩护词模板),律师只需补充关键信息即可使用;此外,产品还支持法律语音文件加密存储,设置访问权限分级,保障案件信息安全,助力法律工作高效开展。语音转写的行业认证包括网络安全等级保护认证,确保产品合规可靠。广州多角色语音转写
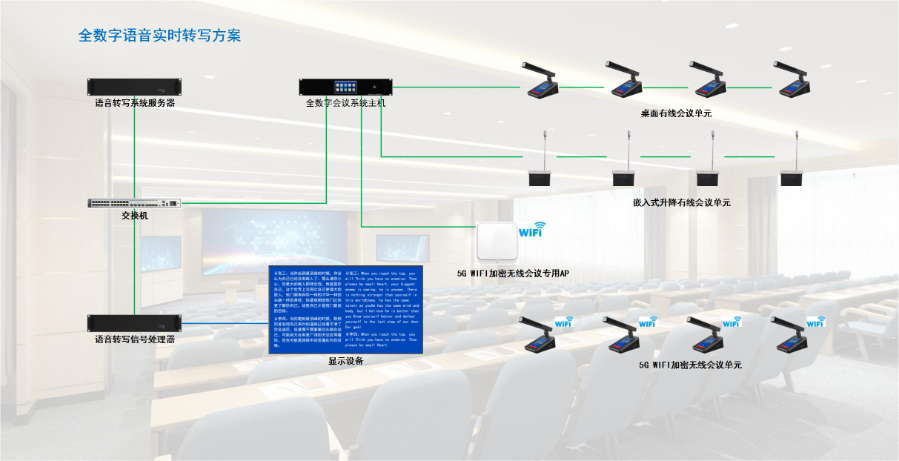
语音转写产品是通过人工智能技术,将人类语音信号实时或离线转化为文字的工具,重心价值在于打破 “听” 与 “读” 的信息传递壁垒,提升信息处理效率。其工作流程包含语音采集、信号预处理、特征提取、模型识别、文字输出五大环节,主流技术基于深度学习中的语音识别模型(如 CNN、RNN、Transformer 架构),可支持多语种、多场景下的精细转写。相比传统人工记录,语音转写产品能实现分钟级处理,准确率普遍达 95% 以上,且可通过个性化训练优化专业领域术语识别。无论是会议记录、课程整理还是采访归档,它都能减少人工重复劳动,让使用者更聚焦于内容本身,而非信息记录环节。广州多语种识别语音转写售后多speaker分离功能让语音转写在多人对话场景中,能区分不同发言者身份。

语音转写产品具备多方面安全保障优势,从数据采集、传输、存储到销毁全流程守护用户隐私,消除用户数据安全顾虑。在数据采集环节,严格遵循 “用户授权才采集” 原则,明确告知用户数据用途,不强制获取无关权限;在数据传输环节,采用端到端加密技术,语音与文字数据传输过程中全程加密,防止中途被窃取或篡改;在数据存储环节,采用分布式加密存储与访问权限分级机制,企业用户可选择本地部署,确保敏感数据不上云;在数据销毁环节,支持定时自动销毁与手动长久删除,删除后通过技术手段彻底清理数据痕迹,无法恢复。同时,产品还定期通过第三方安全审计,符合国家《个人信息保护法》等法规要求,让用户使用更安心。
语音转写产品不能完成语音到文字的基础转化,更具备强大的智能辅助能力,为用户提供超越基础功能的增值价值,这是其区别于传统工具的关键优点。在内容提炼上,可自动提取转写文本中的关键数据、重心观点与待办事项,生成结构化摘要,例如会议转写后自动梳理 “决策事项 - 责任人 - 截止时间” 清单,省去人工筛选时间;在内容优化上,内置 AI 编辑功能,能识别文本中的语法错误、冗余表述,提供优化建议,如将口语化的 “大概、可能” 调整为更严谨的书面语,助力提升文档专业性;在知识关联上,可自动链接转写内容中的专业术语、人名地名,跳转至百科解释或相关资料,例如转写中出现 “量子计算” 时,点击即可查看基础概念,辅助用户理解陌生内容,让转写从 “记录工具” 升级为 “知识处理助手”。医疗语音转写生成的病历可直接导入电子病历系统,减少医护文书撰写时间。

尽管智能语音转写技术取得了明显的发展,但仍然面临着一些挑战.其中一个主要的挑战就是不同口音和方言的识别.世界上存在着繁多复杂的口音和方言,即使是一些主流的智能语音转写系统,对于某些小众或地域性很强的口音也可能会出现识别不准确的情况.此外,同音异形字和多义词的处理也是一个难题.例如,“银行”和“行走”的“行”字,在语音转写时如何准确判断使用者想要表达的正确用字,需要强大的语义理解能力.另外,隐私和数据安全也是智能语音转写面临的问题.由于语音转写涉及用户的语音内容,这些内容可能包含个人隐私信息,如何确保这些信息在转写和存储过程中的安全性,防止信息泄露,是技术开发和相关法律法规需要共同应对的挑战.儿童教育版语音转写含发音评测,标注不准词汇并提供标准读音示范。全数字语音转写字幕
企业版语音转写可对接OA系统,转写文档自动同步至员工工作台账,提升协作效率。广州多角色语音转写
尽管智能语音转写取得了明显进步,但仍然存在一些技术局限亟待解决.一方面,在复杂的环境中,如存在大量背景噪音的情况下,语音转写的准确率会受到一定影响.这是因为背景噪音会干扰语音信号的提取和分析,使得系统难以准确识别语音内容.另一方面,对于一些非常专业、生僻的词汇和领域特定术语,语音转写系统可能无法准确识别.针对这些问题,研究人员正在不断探索新的技术和方法.例如,研发更先进的降噪算法来提高在复杂环境中的识别能力,以及加强特定领域的语料库建设,使系统能够更好地理解和处理专业词汇.未来,智能语音转写技术将朝着更加精细、高效、智能化的方向发展,为用户提供更好的服务.广州多角色语音转写

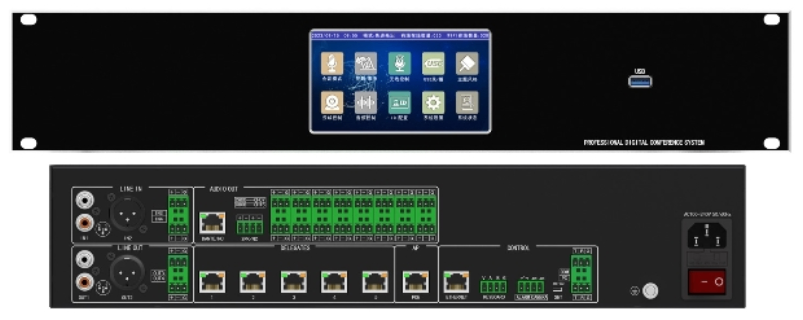
语音转写产品的精细性依赖三大重心技术:声学模型、语言模型与语音活动检测(VAD)。声学模型负责将语音信号转化为音素序列,通过海量语音数据训练,能区分不同口音、语速及背景噪音;语言模型基于语法规则与语义逻辑,优化文字组合合理性,例如避免 “形式” 误写为 “形势”;VAD 技术则可自动识别语音片段与静音时段,剔除无效信息,提升转写效率。部分不错产品还融入实时降噪、多 speaker 分离技术,在嘈杂会议或多人对话场景中,仍能保持清晰转写效果,技术迭代方向正朝着 “低资源语种适配”“跨模态信息融合” 持续推进。自定义词典功能允许用户添加行业术语,适配法律、医疗等专业场景转写需求。北京庭审语音转写语...
- 声音转文字语音转写有什么功能 2026-02-26
- 上海智能翻译语音转写 2026-02-26
- 北京语音转写作用 2026-02-26
- 南京会议纪要语音转写软件系统 2026-02-26
- 北京AI智能语音转写字幕 2026-02-26
- 广州国产化语音转写云平台 2026-02-26
- 上海国产化语音转写同时转写 2026-02-26
- 南京国产化语音转写有什么功能 2026-02-25
- 北京自动记录语音转写怎么样 2026-02-25
- 法院语音转写怎么样 2026-02-25
- 广州全数字语音转写价格 2026-02-25
- 南京文字识别语音转写云平台 2026-02-24
- 上海音频转文字语音转写价格 2026-02-24
- 南京实时语音转写哪家好 2026-02-24
- 广州智能语音转写价格 2026-02-24
- 北京文字识别语音转写好用吗 2026-02-24



- 北京AI智能语音转写字幕 02-26
- 广州国产化语音转写云平台 02-26
- 上海国产化语音转写同时转写 02-26
- 南京国产化语音转写有什么功能 02-25
- 北京自动记录语音转写怎么样 02-25
- 法院语音转写怎么样 02-25
- 长沙智能语音转写同时转写 02-25
- 上海庭审语音转写故障排除 02-25
- 北京自动翻译语音转写系统 02-25
- 北京无纸化语音转写价格 02-25