- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
智能语音转写与人们的生活融合是未来的发展趋势.想象一下,在日常生活中,我们随时随地都可以通过语音转写来方便地记录信息.当我们在购物时,通过语音转写可以快速记录下商品的价格、型号等信息;当我们在旅游时,它能帮助我们记录下旅途中的所见所感,生成详细的旅行日记.在工作中,无论是办公会议、项目讨论还是客户沟通,语音转写都能实时帮我们整理会议记录,提高工作效率.而且,智能语音转写与智能家居、智能车载系统等的结合,将为人们创造更加便捷、舒适的生活环境.比如,在驾车过程中,我们可以通过语音转写快速记录重要信息,而不用担心分心操作手机或其他设备,让整个交流过程更加顺畅和自然.语音转写的方言适配覆盖粤语、四川话等,通过口音训练提升识别准确率。北京语音转写
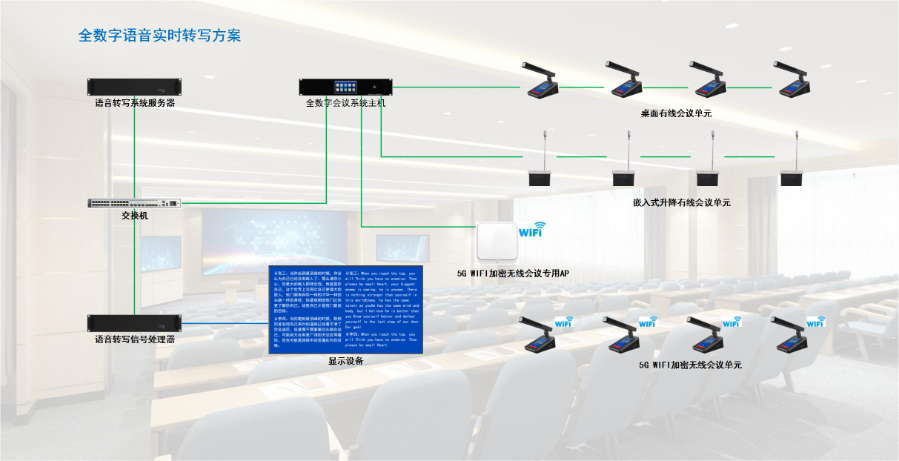
为应对网络中断、设备故障等突发场景,语音转写产品设计了完善的应急方案。在网络中断场景,支持 “离线缓存 + 联网同步” 功能,网络断开时,转写内容自动存储在本地设备,待网络恢复后,系统自动将本地数据同步至云端,避免内容丢失;在设备故障场景,推出 “跨设备备份” 功能,用户可提前开启自动备份,转写文档实时同步至关联设备(如手机端转写内容同步至电脑端),若当前设备故障,可通过其他设备继续编辑、导出文档;此外,产品还提供 “应急恢复工具”,若转写过程中意外退出,重新打开产品时,系统可自动检测并恢复未保存的转写内容,同时支持手动导入临时缓存文件,较大限度减少突发情况造成的损失,保障用户使用过程稳定可靠。北京自动翻译语音转写故障排除借助语音转写功能,医生可以将患者的口述病情快速转写成病历。

语音转写产品遵循清晰的版本更新与功能迭代逻辑,确保产品持续满足用户需求。版本更新分为 “常规更新” 与 “重大更新”:常规更新每月 1-2 次,主要修复已知 bug、优化现有功能(如提升特定口音转写准确率、优化文档导出速度),更新包体积小,不影响用户正常使用;重大更新每季度 1 次,推出全新重心功能(如新增情感识别、多语种互转),同时对界面进行优化升级,提升用户体验。功能迭代逻辑以用户需求为重心:先通过用户反馈渠道、市场调研收集需求,按 “高频需求优先、重要需求重点投入” 原则排序;再由技术团队评估可行性,制定迭代方案;开发完成后,先在小范围用户群体中进行测试,收集使用反馈并调整;较后正式上线,同时提供新功能使用教程,确保用户能快速掌握。
语音转写产品较重心的优点在于较好的效率提升,彻底改变传统人工记录的低效模式。传统人工记录会议、采访或课程内容时,不需全程专注避免遗漏,后续整理还需逐句核对、补全信息,1 小时的语音内容往往需要 3-4 小时才能整理成完整文字;而语音转写产品可实现 “语音结束即出文字”,1 小时语音较快 5 分钟内完成转写,且支持实时转写模式,会议或课程进行中就能同步生成文字记录,会后无需额外整理,直接导出可用文档。这种效率优势让使用者从繁琐的记录工作中解放,将更多时间投入到内容分析、思考决策等重心事务中,尤其适合高频处理语音信息的职场人、教育工作者与创作者。语音转写支持批量处理音频,一次性导入多段文件,设备空闲时自动完成转写。

正规语音转写产品需符合多项行业标准并获取合规认证,保障产品质量与用户权益。在技术标准上,需符合国家《信息安全技术 语音交互系统安全技术要求》,确保语音数据处理过程安全、规范,同时遵循语音识别准确率、响应速度等性能标准;在数据合规方面,需通过《个人信息保护法》合规认证,明确语音数据采集、存储、使用的边界,获取用户明确授权;在行业特定认证上,面向医疗领域的产品需通过医疗行业信息安全认证,面向教育领域的产品需符合教育数据管理规范。此外,部分国际市场的产品还需获取国外合规认证(如欧盟 GDPR 认证),确保在跨境使用场景中符合当地法规。用户选择产品时,可查看产品认证资质,选择合规、可靠的服务。语音转写的表情符号匹配功能根据语音情绪推荐表情,让内容表达更生动。北京多角色语音转写售后维护
心理咨询场景中,语音转写加密存储对话,自动隐去来访者隐私信息。北京语音转写
语音转写产品正探索多模态融合技术,打破单一语音转文字的局限。技术层面,将语音转写与图像识别、语义理解结合,例如在线上会议场景,产品可同时识别语音内容与屏幕共享的 PPT 文字,将二者关联整合,转写文档中不有语音文字,还能插入对应 PPT 页面截图及关键文字提取,让会议记录更完整;在教育培训场景,支持 “语音 + 板书” 同步转写,通过摄像头捕捉教师板书内容,结合语音转写,生成 “语音文字 + 板书图像 + 文字提取” 的综合笔记,方便学生复习时对照理解;此外,部分产品还融入手势识别技术,用户在演讲时通过特定手势(如抬手暂停、挥手继续),即可控制转写启停,实现更自然的人机交互,拓展产品应用形态。北京语音转写
语音转写产品的精细性依赖三大重心技术:声学模型、语言模型与语音活动检测(VAD)。声学模型负责将语音信号转化为音素序列,通过海量语音数据训练,能区分不同口音、语速及背景噪音;语言模型基于语法规则与语义逻辑,优化文字组合合理性,例如避免 “形式” 误写为 “形势”;VAD 技术则可自动识别语音片段与静音时段,剔除无效信息,提升转写效率。部分不错产品还融入实时降噪、多 speaker 分离技术,在嘈杂会议或多人对话场景中,仍能保持清晰转写效果,技术迭代方向正朝着 “低资源语种适配”“跨模态信息融合” 持续推进。自定义词典功能允许用户添加行业术语,适配法律、医疗等专业场景转写需求。北京庭审语音转写语...
- 声音转文字语音转写有什么功能 2026-02-26
- 上海智能翻译语音转写 2026-02-26
- 北京AI智能语音转写字幕 2026-02-26
- 上海国产化语音转写同时转写 2026-02-26
- 南京国产化语音转写有什么功能 2026-02-25
- 北京自动记录语音转写怎么样 2026-02-25
- 法院语音转写怎么样 2026-02-25
- 长沙智能语音转写同时转写 2026-02-25
- 上海庭审语音转写故障排除 2026-02-25
- 北京自动翻译语音转写系统 2026-02-25


- 南京实时语音转写哪家好 2026-02-24
- 广州智能语音转写价格 2026-02-24
- 北京文字识别语音转写好用吗 2026-02-24
- 北京自动翻译语音转写怎么样 2026-02-24
- 北京自动记录语音转写哪家好 2026-02-24
- 南京国产化语音转写哪家好 2026-02-24




- 南京国产化语音转写有什么功能 02-25
- 北京自动记录语音转写怎么样 02-25
- 法院语音转写怎么样 02-25
- 长沙智能语音转写同时转写 02-25
- 上海庭审语音转写故障排除 02-25
- 北京自动翻译语音转写系统 02-25
- 北京无纸化语音转写价格 02-25
- 广州全数字语音转写价格 02-25
- 南京文字识别语音转写云平台 02-24
- 上海音频转文字语音转写价格 02-24