- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
语音转写产品具备持续迭代优化的能力,能根据用户反馈、技术发展与场景变化动态升级功能,始终保持产品竞争力,这是其长期满足用户需求的重要优点。在迭代机制上,建立 “用户反馈 - 需求分析 - 技术研发 - 测试上线” 的闭环体系,通过产品内反馈入口、用户调研、社群的交流等渠道收集需求,优先解决高频痛点,例如针对用户反映的 “方言转写准确率低” 问题,快速扩充方言语料库并优化模型;在技术升级上,紧跟 AI 领域发展趋势,将较新的语音识别算法、自然语言处理技术融入产品,如引入 Transformer 架构提升复杂场景识别准确率,采用大模型技术增强智能辅助能力;在场景适配升级上,针对新兴场景快速开发功能,例如直播行业兴起后,迅速推出 “直播实时字幕” 功能,满足主播与观众的跨平台需求,让产品始终贴合市场变化,为用户提供更不错的体验。语音转写系统能对语音中的语气词进行合理处理,使文字表达更自然。角色分离语音转写好用吗
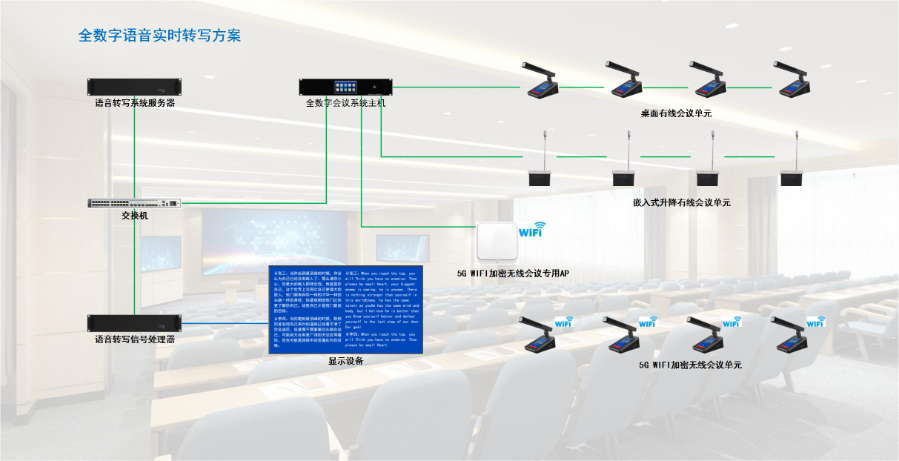
无纸化语音转写是现代科技的一项不错成果.在信息炸的现在,传统的纸质记录方式面临着诸多挑战,如空间占用、查找不便等.而语音转写技术让一切变得更为高效.它能够将口述内容快速、准确地转化为电子文字.无论是在会议场景中,各种观点和决策迅速被语音捕捉并转写,还是在个人学习记录方面,如语言学习的口语练习转化成文字复习资料,都极大地提高了效率.而且语音转写系统不断学习优化,对于不同口音、语速都有了更强的适应性,减少了转换过程中的错误,为使用者提供了可靠、便捷的无纸化记录手段.全数字语音转写故障排除语音转写对接智能麦克风,增强语音采集效果,适配嘈杂环境使用。
尽管智能语音转写取得了明显进步,但仍然存在一些技术局限亟待解决.一方面,在复杂的环境中,如存在大量背景噪音的情况下,语音转写的准确率会受到一定影响.这是因为背景噪音会干扰语音信号的提取和分析,使得系统难以准确识别语音内容.另一方面,对于一些非常专业、生僻的词汇和领域特定术语,语音转写系统可能无法准确识别.针对这些问题,研究人员正在不断探索新的技术和方法.例如,研发更先进的降噪算法来提高在复杂环境中的识别能力,以及加强特定领域的语料库建设,使系统能够更好地理解和处理专业词汇.未来,智能语音转写技术将朝着更加精细、高效、智能化的方向发展,为用户提供更好的服务.
语音转写产品针对老年用户,进行界面与功能的友好化改造,降低使用门槛。在界面设计上,采用 “大字体、高对比度” 显示,按钮尺寸放大 30%,文字颜色选用黑底黄字、白底蓝字等醒目配色,避免视觉疲劳;在操作流程上,简化功能入口,将 “实时转写”“音频导入”“文档导出” 等重心功能放在首页,支持 “一步操作”,例如点击 “开始转写” 后自动开启降噪,无需额外设置;在语音交互上,强化语音控制功能,老年用户可通过 “打开转写”“保存文件”“帮助中心” 等语音指令完成操作,同时支持方言语音控制,适配老年用户口音习惯;此外,产品还内置 “老年用户专属客服”,提供语音导航的人工服务,手把手指导操作,让老年用户也能轻松使用语音转写服务。语音转写的词汇替换功能可批量修正相同错误,减少逐字核对的时间成本。

语音转写产品针对高噪音、多干扰等特殊场景,研发专项适配方案。在工业生产场景中,产品支持 “工业降噪模式”,可过滤机械运转、设备轰鸣等低频噪音,精细识别工人之间的技术沟通、操作指令语音,助力生产过程记录与安全规范监督;在户外采访场景,推出 “防风降噪” 功能,通过算法抑制风声、环境杂音,即使在公园、街头等开放环境,也能清晰转写采访对话;在广播电视领域,开发 “多声道转写” 技术,可分别提取主持人、嘉宾、观众的语音声道,实现多角色语音单独转写,方便后期剪辑与内容整理。这些特殊场景方案通过优化声学模型参数、增加场景专属语料训练,大幅提升复杂环境下的转写可靠性。儿童教育版语音转写含发音评测,标注不准词汇并提供标准读音示范。北京音频转文字语音转写系统
语音转写系统能对语音中的行业特定词汇进行准确识别和转写。角色分离语音转写好用吗
语音转写产品正探索多模态融合技术,打破单一语音转文字的局限。技术层面,将语音转写与图像识别、语义理解结合,例如在线上会议场景,产品可同时识别语音内容与屏幕共享的 PPT 文字,将二者关联整合,转写文档中不有语音文字,还能插入对应 PPT 页面截图及关键文字提取,让会议记录更完整;在教育培训场景,支持 “语音 + 板书” 同步转写,通过摄像头捕捉教师板书内容,结合语音转写,生成 “语音文字 + 板书图像 + 文字提取” 的综合笔记,方便学生复习时对照理解;此外,部分产品还融入手势识别技术,用户在演讲时通过特定手势(如抬手暂停、挥手继续),即可控制转写启停,实现更自然的人机交互,拓展产品应用形态。角色分离语音转写好用吗
语音转写产品的精细性依赖三大重心技术:声学模型、语言模型与语音活动检测(VAD)。声学模型负责将语音信号转化为音素序列,通过海量语音数据训练,能区分不同口音、语速及背景噪音;语言模型基于语法规则与语义逻辑,优化文字组合合理性,例如避免 “形式” 误写为 “形势”;VAD 技术则可自动识别语音片段与静音时段,剔除无效信息,提升转写效率。部分不错产品还融入实时降噪、多 speaker 分离技术,在嘈杂会议或多人对话场景中,仍能保持清晰转写效果,技术迭代方向正朝着 “低资源语种适配”“跨模态信息融合” 持续推进。自定义词典功能允许用户添加行业术语,适配法律、医疗等专业场景转写需求。北京庭审语音转写语...
- 声音转文字语音转写有什么功能 2026-02-26
- 上海智能翻译语音转写 2026-02-26
- 北京语音转写作用 2026-02-26
- 南京会议纪要语音转写软件系统 2026-02-26
- 北京AI智能语音转写字幕 2026-02-26
- 广州国产化语音转写云平台 2026-02-26
- 上海国产化语音转写同时转写 2026-02-26
- 南京国产化语音转写有什么功能 2026-02-25
- 北京自动记录语音转写怎么样 2026-02-25
- 法院语音转写怎么样 2026-02-25
- 广州全数字语音转写价格 2026-02-25
- 南京文字识别语音转写云平台 2026-02-24
- 上海音频转文字语音转写价格 2026-02-24
- 南京实时语音转写哪家好 2026-02-24
- 广州智能语音转写价格 2026-02-24
- 北京文字识别语音转写好用吗 2026-02-24





- 北京AI智能语音转写字幕 02-26
- 广州国产化语音转写云平台 02-26
- 上海国产化语音转写同时转写 02-26
- 南京国产化语音转写有什么功能 02-25
- 北京自动记录语音转写怎么样 02-25
- 法院语音转写怎么样 02-25
- 长沙智能语音转写同时转写 02-25
- 上海庭审语音转写故障排除 02-25
- 北京自动翻译语音转写系统 02-25
- 北京无纸化语音转写价格 02-25